Processing registrations in bulk is done by uploading CSV files. These files are plain text files which can contain multiple registrations at once and are extracted from your primary system.
The first step is to create the file correctly.
Using a CSV editor
While Excel is a fine tool to view CSV’s, we do not recommend it to edit CSVs. Instead use notepad++ or any other text editor. Here are a few risks you should be aware of when editing a CSV in Excel. Excel will interpret the content, which may lead to changes:
- Leading zeros disappear in fields that are recognized as numeric fields
- Entries like 3-9 can become March-9
- The only accepted date format DD/MM/YYYY can be modified (e.g. To DD/MM/YY)
- The decimal separator can differ from that in HD4DP, a semicolon wil lead to a correct upload
- When saving a file as .csv, Excel uses the default field separator. HD4DP only accepts CSV with a semicolon as separator. This default setting can be adapted in the properties of your computer.
- CSV encoding must be in UTF-8.
Setting up the document
Every column in the CSV file needs to be recognized as a field of the register by the HD4DP application. Therefor each column in the file must be identical by the technical name of the field in the register.
Tip: Downloading (manually) entered data from HD4DP will guide you in formatting a CSV file and may help during the development of the CSV extraction from the primary systems.
The Data Collection Definition (DCD) specifications for a register and its fields are defined and documented on this documentation portal.
Each field in the form can be completed through a value in a CSV file.
An example field is “Date of last follow-up”, shown in the screenshot below.
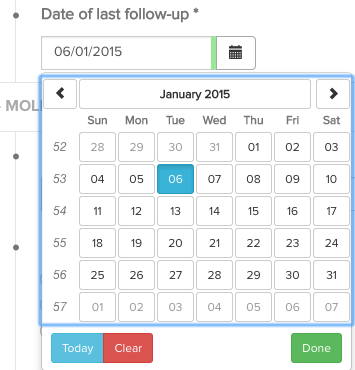
This field is of the type “date” and is required (*). Within the technical documentation of this data collection, this is shown as follows:
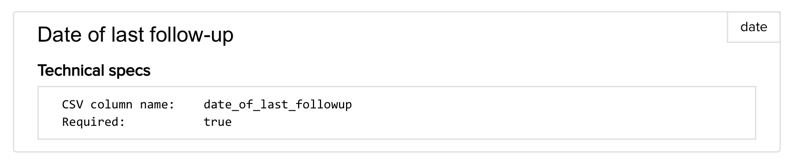
To include this field in a CSV upload file, it is sufficient to create a column with the name “date_of_last_followup” and populate it with the appropriate data i.e. a date in the format dd/mm/yyyy.
Fields can be required, read-only and computed (automatically calculated). Fields can also have a default value.
This information is present in the detailed technical description for each data collection.
General requirements
- The column separator is the semicolon (;)
- The decimal separator for numbers is the comma (,)
- The date format is dd/mm/yyyy
Basic content types
Depending on the type of the field, a different representation of the data is expected. The table below describes the different basic types and the rules on how to provide the content for these types.
| Content type | Expected format/content |
| boolean | TRUE, FALSE |
| date | dd/mm/yyyy |
| choice | code from choice list |
| list | option1_label|option2_label|etc. |
| multiline | free text |
| number | number (decimal separator = ,) |
| patientID | SSIN number. If the person does not have a SSIN, leave this field blank. |
| questionnaire | code from questionnaire answer list |
| text | ● free text ● if a binding reference list is used: a code from the reference list ● if a non-binding reference list is used: a code from the reference list or free text |
| attachment | ● expected format/content: Name of the file that must be attached (e.g. protocol.txt). ● expected extension: .txt ● file must be stored in the same folder as the folder that is used for the CSV-upload |
Advanced content types
Other than these simple types, more complex data structures can be used, as shown in the table below. Each of these types is explained in more detail below the table.
| Content type | CSV column name | Expected format |
| fields within fieldset | fieldset_label|field_label | depending on the field type |
| list (1 field) | list_label|field | value1|value2|etc |
| list (block of fields) | list_label|0|field1 list_label|0|field2 list_label|1|field1 list_label|1|field2 etc. | depending on the field type |
| nested fields below choice or multichoice | choice_label|nested_item | depending on the field type |
Fieldset
A fieldset is a collection of fields, as shown in the image below:
Anthropometry is the title of the fieldset, and this fieldset contains two fields, weight and height. Fieldsets fieldsets do not have a number cfr. image below - Anthropometry.
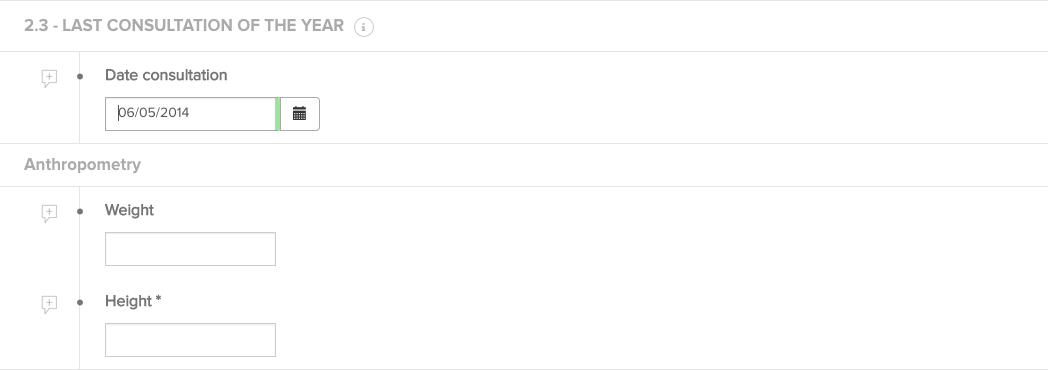
Sections do not have an impact on the CSV file, whereas fieldsets do. The title of the fieldset must be included in the field name column as follows: fieldset_label|field_label.
E.g. for the two Anthropometry fieldset fields weight and height below, the correct CSV column headers are: anthropometry|weight en anthropometry|height.
Lists
A list is also a collection of fields, like a fieldset, but with the additional property that the collection of fields can be repeated.
An example is shown in the image below: “Birthdays of the biological children for this patient” is a list. One list item consists of two fields, “Child birth month” and “Child birth year”. For each child, a list item can be added.
The CSV column names consist of the list header label and the field label (as for fieldsets), together with a counter to distinguish the different list items. The correct CSV column names for the two list items below are:
- birthdays_of_the_biological_children_for_this_patient|00|child_birth_month
- birthdays_of_the_biological_children_for_this_patient|00|child_birth_month
- birthdays_of_the_biological_children_for_this_patient|01|child_birth_month
- birthdays_of_the_biological_children_for_this_patient|01|child_birth_year
Please note that for every line, the numbers should increment, starting from 0 (|00|,|01|, .. is ok, |01|, |03|, ... is not). You can't have blank values for |00| and filled values for a higher number.
Please note that the numbering requires a stable format, meaning the number of characters used by the number has to be constant. You can't have one record using |00| and another using |0|. Generally we advice to use a string length of 2 digits.

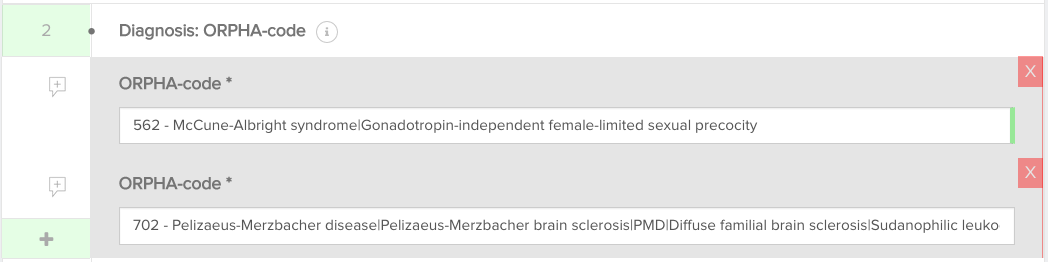
For lists consisting of 1 field a simplified implementation is possible. The CSV column header only consists of the list header label and multiple values are provided in the one column, separated by a pipe (|).
E.g. for the list in the image below, the CSV column header is diagnosis_orphacode and the content of the column is 562|702. This is the example of a text field with a reference list: providing the codes of the reference list is sufficient.
Nested fields
Nested fields are fields that only become available when specific options are selected in the form. An example is shown below: the field “Specify” only becomes available if the checkbox “Other” is marked. These fields also have a combined CSV column header, consisting of the choice list label and the field label. For the example below, the correct CSV column header is hence base_of_diagnosis|specify.

Attachments
When a CSV is prepared and put in the provisioning folder, it can contain references to attachments for data collections that specifically allow this.
These references are relative paths to the file location. If such a reference is present in the CSV file, the attachment content is uploaded and linked to the created registration. The attachment is then available in the HD4DP client as well as in the HD4RES client when the registration is submitted.
The maximum file size for attachments is 6 MB.
If a data collection permits you to send attachments you should have the column name to use in the CSV. If not, you should be able to find it at https://www.healthdata.be/dcd/#/collections or you can contact Support.Healthdata@sciensano.be.
Add the column name to the header of the CSV and add the file names as values in the column.
Example: “picture.png”
Put the CSV file in the correct provisioning folder (organization sub folder, then in the register sub folder), along with a “picture.png” file of your choice. The application picks the CSV file and creates a new registration.
Open the registration and verify the attachment has correctly been uploaded.